

One MCP that saves me time
How one real problem turned a "solution in search of a problem" into a productivity gain

For months, I'd been tinkering with MCP servers on Claude Desktop: Notion, n8n, Context7. They felt interesting, but no use case has blown me away.
Most of them felt like a solution in search for real problems. It’s like in product management, I get excited about the solution in the beginning and later I realise that the problem or the objective were not clear at all. I was clearly trying these MCPs to scratch imaginary itches…
Problem-First AI approach
This made me realise that I needed a better and repeatable approach (nothing new, just product management in action):
Start with a real problem - start with work that actually frustrates me
Prototype with constraints - begin small to build confidence and validate outputs
Scale incrementally - extend proven approaches to similar problems
Last week, the problems found me. I needed to:
Audit a 50-page website with 100+ embedded links to identify document templates
Merge four training pages into one restructured page
Suddenly, an MCP wasn’t just a novelty tool, it was exactly what I needed.
Problem 1: Website audit
I started with my traditional approach: Half a day with Screaming Frog crawler plus manual mapping. Painfully slow, made me feel like a human copy-paste machine and no much value beyond the initial discovery.
On my desk I have a post-it note that says “Can you do this with AI?” to remind me to take a step back and think AI first - see Unlearning Experiment article. As I remembered about reading a few days ago about Firecrawl MCP, I was sure that Claude with a proper crawler would do a faster, and potentially better job than me. Fifteen minutes later, I ended up with this setup:
Firecrawl MCP installed on my Claude Desktop, details about this in their docs
A dedicated Project, so Claude can understand how this work was fitting inside the bigger picture: product strategy doc, user pain points, roadmap etc.
As this was the first time using this Firecrawl MCP, I decided to take baby steps to build trust, learn and improve the approach along the way.
Step 1: Build trust with Firecrawl MCP & Claude
At this stage my confidence was not very high, I was still unsure if I was getting any value out of Claude + Firecrawl MCP. Were they going to scrape all the content properly?
So, I decided to start small with a single website folder that had pagination. This helped to limit the Claude tokens burn and the Firecrawl credits use. Plus, it was easier for me check the output - a list of all the pages in the folder with all the embedded links for each page.
The prompt I used, nothing fancy:
I need you to crawl this website folder, and list all the links found on each page: [website folder url].First, it mapped out all the pages in the folder:

Then it went to scrape all the pages, one by one:
When I saw how the pages were crawled and the final result, I felt that I was onto something. For each page, Claude has listed all the embedded links and enriched the data without me asking for it: added the title of the link, and a mix of where the content was hosted (Google Drive, website name) and the file type (PDF, Google Docs etc.). It was far from perfect, but it made me think about the prompt for the next step.
Doing this manually it would have taken me at least 30 minutes. With Claude + Firecrawl it took me less than 2 minutes.
Step 2: Identify which resources are templates
I wanted to check if Claude + Firecrawl MCP can easily identify which resource can be used as an editable template.
Please analyse each of the above links to identify which ones contain editable templates rather than just informational resources. For each link, check if it offers:
Primary criteria (must have at least one):
* Fillable PDF forms with input fields
* Downloadable document templates (Word, Excel, PowerPoint, etc.)
* Interactive web forms that generate customised outputs
* Template files with placeholder text/fields to be replaced
Secondary indicators:
* Titles containing words like "template," "worksheet," "planner," "generator," "calculator," "form"
* Clear instructions for customisation/personalisation
* Examples showing before/after or blank vs. filled versions
Exclude resources that are:
* Pure educational content (articles, guides, tutorials)
* Static examples without editable elements
* Tools that require significant design skills to customise
For each qualifying link, provide:
1. URL
2. Template type (PDF form, Word doc, web tool, etc.)
3. Brief description of what can be customised
4. Ease of use rating (Easy/Medium/Advanced)
Focus on templates that an average user could quickly fill out or customise without specialised software or design skills.See a sample of the output:

At the first glance, the results were very good and what I asked for, as Claude identified and categorised the editable templates.
Step 3: Extend the analysis
This was just a matter of giving Claude the next folders URLs to be crawl and asking for a checkpoint before going ahead, making sure that it had all the URLs for each folder.
Please extend the analysis to all URLs that exist in these folders:
* URL 1 (it has pagination)
* URL 2 (this has pages nested, 2 levels down)
* URL 3
* etc
Before you start the analysis, show me all the pages URLs that you are going to crawlThere were a few more iterations to improve the output formatting that I turned into a Word document - with the proper polishing and revisions from my side.
Things that didn’t go as expected
Google Drive login issue
For one PDF on a Google Drive, that I could easily access and download manually, Firecrawl was asked to authenticate.

As I tried to debug this, in another chat, I asked Claude to scrape the same Google Drive URL with Firecrawl and it worked just fine…. So, make sure you check what Firecrawl and Claude are doing 🔎.
Claude limited the numbers of crawled URLs
At one point I noticed that Claude crawled only 8 URLs out of a 55+ in scope. So I came back to Claude:
How did you decide to run a deep analysis only on 8 resources, and exclude the other ones?See how Claude is rationalising the results, this makes sense, if I want to do a “vibe” check of the templates and I’m happy with ~80% accuracy.

And please note what Claude said that it should have done: “Systematic analysis of ALL 55+ links - check every single resource regardless of title”
When I asked Claude to crawl all the URLs, it still didn’t do it 🤦♂️.

At this point I had a decision to make:
Spend more time and resources trying to make Claude crawl each and one of the links
Manually check the accuracy by sampling the data
As this isn't a regular process for me, and I didn’t need 100% accuracy, I realised that route #1 would have taken me too much time to solve it, therefore decided to take #2.
Problem 2: Merge four pages into one
With my confidence built, I decided to move to the second challenge. We had a training section on the website with four dedicated pages for each training provider. Talking to users we realised that this structure was reflecting the internal organisation, rather than users’ needs. Next step was to bring everything into a single page and restructure the information based on the training topics, rather than providers.
The traditional approach I would have taken was to copy the content from each page in a Google Doc and give it Claude to help me restructure it.
Instead of doing that, I asked Claude to do it all for me:
# Ask
I need help to restructure the content from these web pages into a single one:
* URL 1
* URL 2
* URL 3
* URL 4
## Step 1
Scrape the pages using Firecrawl so you have all the content before you restructure it into a single page.
Create an artifact where you have the content of all the pages you've scraped. The output format:
* Page name
* Page URL
* Page content
## Step 2
Create the new page using the content from Step 1 and put it into a second artifact.
# Context:
[insert context]As you can see below, Claude followed my instructions:
it scraped the content from all the pages using Firecrawl
created an artifact with this content so I can check it
created a second artifact with the new restructured content
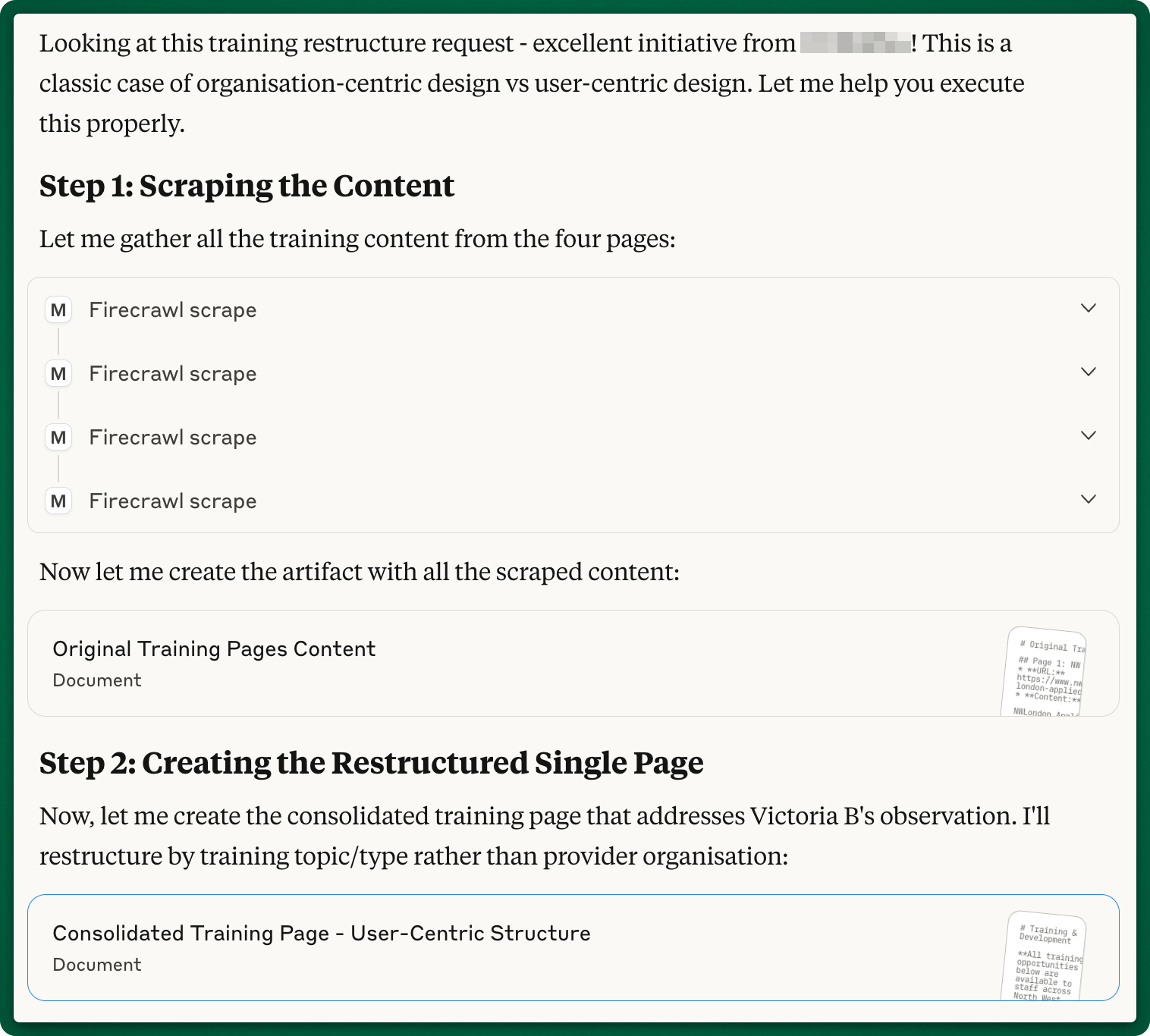
Based on the draft done by Claude, I created the new page and published it, but kept it hidden from the users. This made it very easy for me to ask Claude to QA the new page:
I created this new page: [URL]
Please scrape the page (using firecrawl) again and look for any errors or inconsistencies. I may have left some placeholders on the page. Scan it thoroughly and help me with any improvements ideas for the page.Claude instantly identified issues and it really felt like sending to review to a fellow human, but with the benefit of receiving feedback in 30 seconds:
missing content - who should attend and training providers
inconsistent formatting - it noticed that I copy-pasted the content from one section to another and suggested changes
in a series of workshops, it identified that I used the same date for two different sessions

Bonus problem: reviewing Substack posts
When I finish a post draft I start working with Claude to refine it. And usually, I copy-paste the content and go from there. But, as I was writing about content scraping, I thought “Why not bring the content via Firecrawl, using the Secret draft link?”
I went and I asked Claude to bring this post into it’s context window and took it from there. I might say that I’m quite pleased with this new workflow 😎.
Please scrape this page [URL] using Firecrawl.What I learned
Problem-first beats solution-first: this is how I’m trying to always approach the product work and it was a good reminder to do this in every aspect of my work
Start small to build confidence: beginning with a single website folder helped me validate the approach before scaling up
AI excels at tedious, structured work: tasks like crawling 50+ pages and cataloging 100+ embedded links went from 4-5 hours of work to 30 minutes
Always validate AI outputs: Claude made selective decisions (crawling only 8 of 55 URLs) and Firecrawl had authentication issues that required human oversight
I created a repeatable workflow that saves me time: now, whenever I see website content that I need to work with, Firecrawl MCP + Claude come to mind first 😉.
This is not 10x productivity booster, but delegating tedious work to Firecrawl and Claude it saves me at least 30% of my time, and most importantly it saves my sanity.
And please remember the Problem-First AI approach:
Start with a real problem - start with work that actually frustrates me
Prototype with constraints - begin small to build confidence and validate outputs
Scale incrementally - extend proven approaches to similar problems
Let’s tinker. Together.
Ady,
Tinkerer in Residence